Automate your Data Scraping with Apache Airflow and Beautiful Soup
Learn how to easily automate your LinkedIn Scraping with Airflow and Beautiful Soup.


Learn how to easily automate your LinkedIn Scraping with Airflow and Beautiful Soup.
“Data” is changing the face of our world. It might be part of a study helping to cure a disease, boost a company’s revenue, make a building more efficient or drive ads that you keep seeing. To take advantage of data, the first step is to gather it and that’s where web scraping comes in.
This recipe teaches you how to easily build an automatic data scraping pipeline using open source technologies. In particular, you will be able to scrape user profiles in LinkedIn and move these profiles into a relational database such as PostgreSQL. You can then use this data to drive geo-specific marketing campaigns or raise awareness for a new product feature based on job titles.
Prerequisites
Below are the prerequisite tools you’ll need to build your own LinkedIn profile data scraper:
Here is a quick command-line snippet that can help you install Apache Airflow on your local machine:
Initiate the Airflow DB by running the following command:
Create a user for Airflow using the following command while making sure to update the required values with your own.
Once the packages are installed start the airflow web server and scheduler by running the following commands in two separate terminal windows. Ensure that the virtual environment is active in both windows.
Once the setup is complete, visit http://localhost:8080 to access the Airflow Web UI.
Enter the credentials used to create the user in the previous step. Once logged in you will have access to the Airflow UI as shown below.
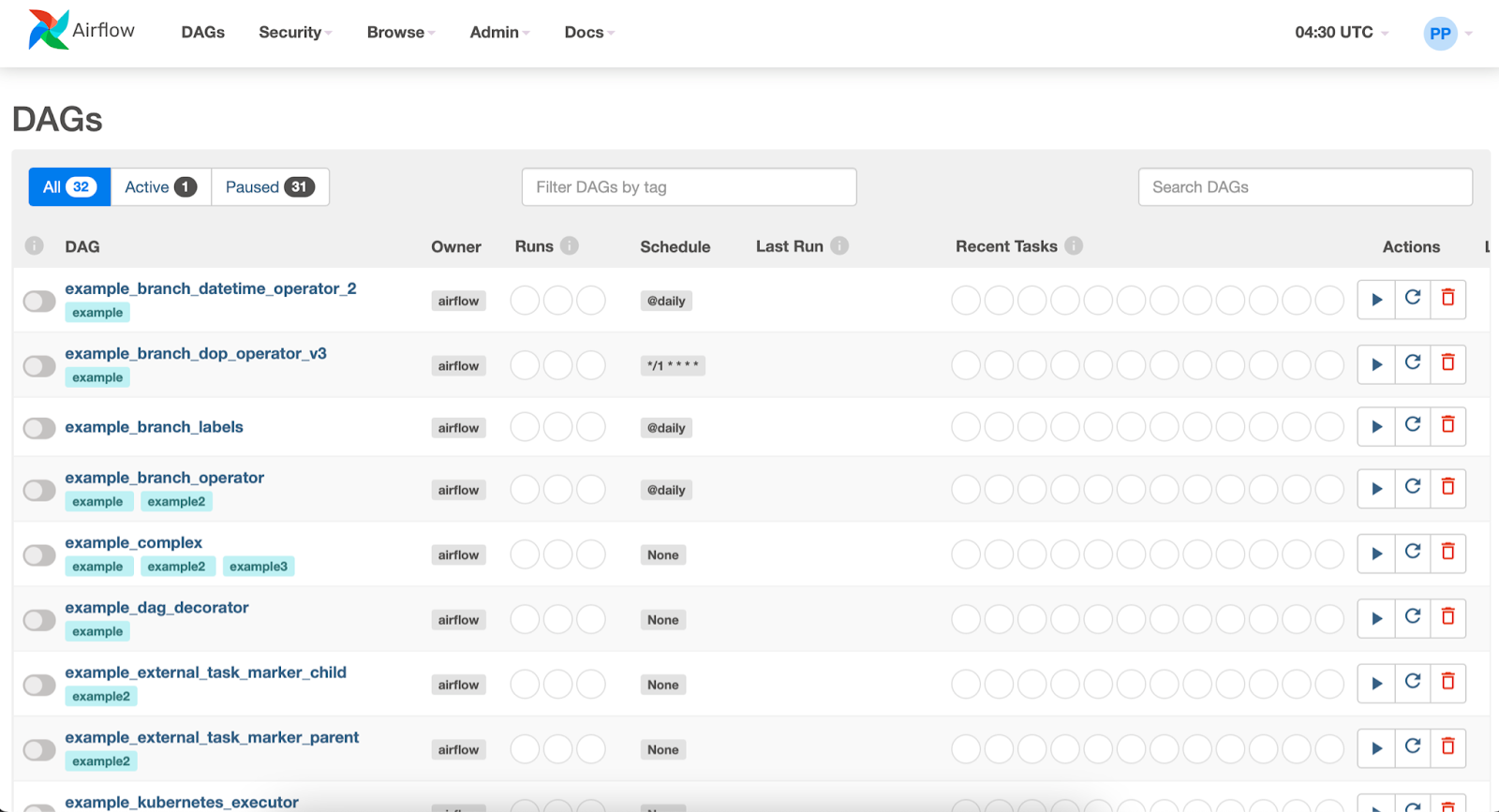
In this recipe, the python scraper will parse and process the LinkedIn page and store data in JSON to be loaded into PostgreSQL. It will then trigger an Airbyte connection that will migrate the scraped data from that file to a PostgreSQL database.
Setup the source for Airbyte by going to Connections > new connection.
Provide a name for the source, and select Source Type as File and then Local Filesystem under provider.
This input file needed by Airbyte needs to be located at the following physical local machine mount path (/tmp/airbyte_local/) which Airbyte mounts to ‘/local’. In this example, we have created a subdirectory under that physical mount path called linkedin and a JSON file called linkedin.json.
The effective logical URL that you can use in Airbyte is /local/linkedin/linkedin.json.
The source configuration should look something like this:
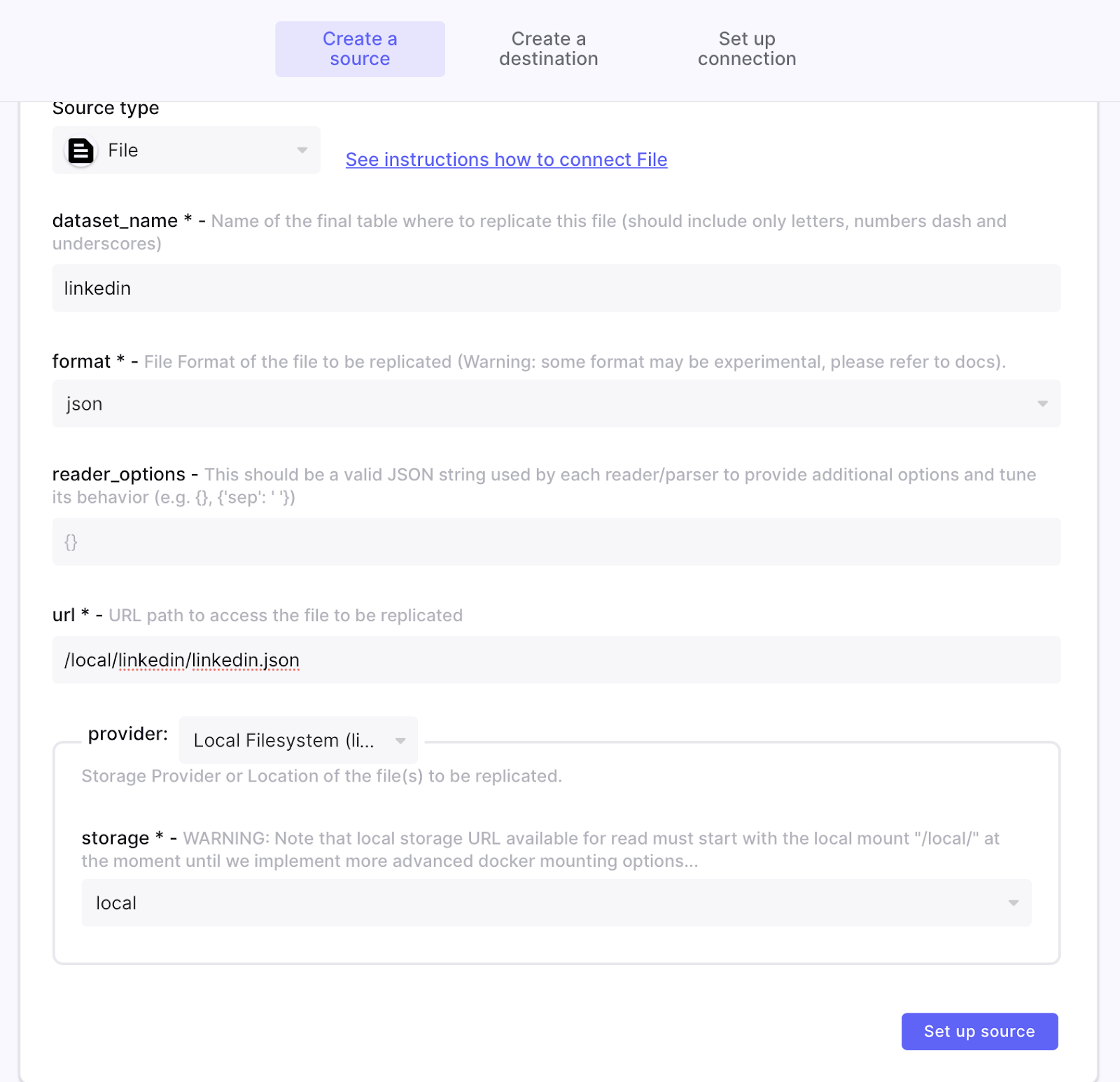
Once the file source is properly configured, the connection can be tested.

Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.

The next step is to configure the destination for the scraped data, in this case a PostgreSQL database. If you do not have PostgreSQL set up, you can quickly set one with docker using the following command:
Once you have PostgreSQL running, you will need a database created that will be used by Airbyte to write the data. Run the following commands to connect to PostgreSQL and create a new database called linkedin.
In the Airbyte UI select PostgreSQL as your destination and enter the following values for your configuration.
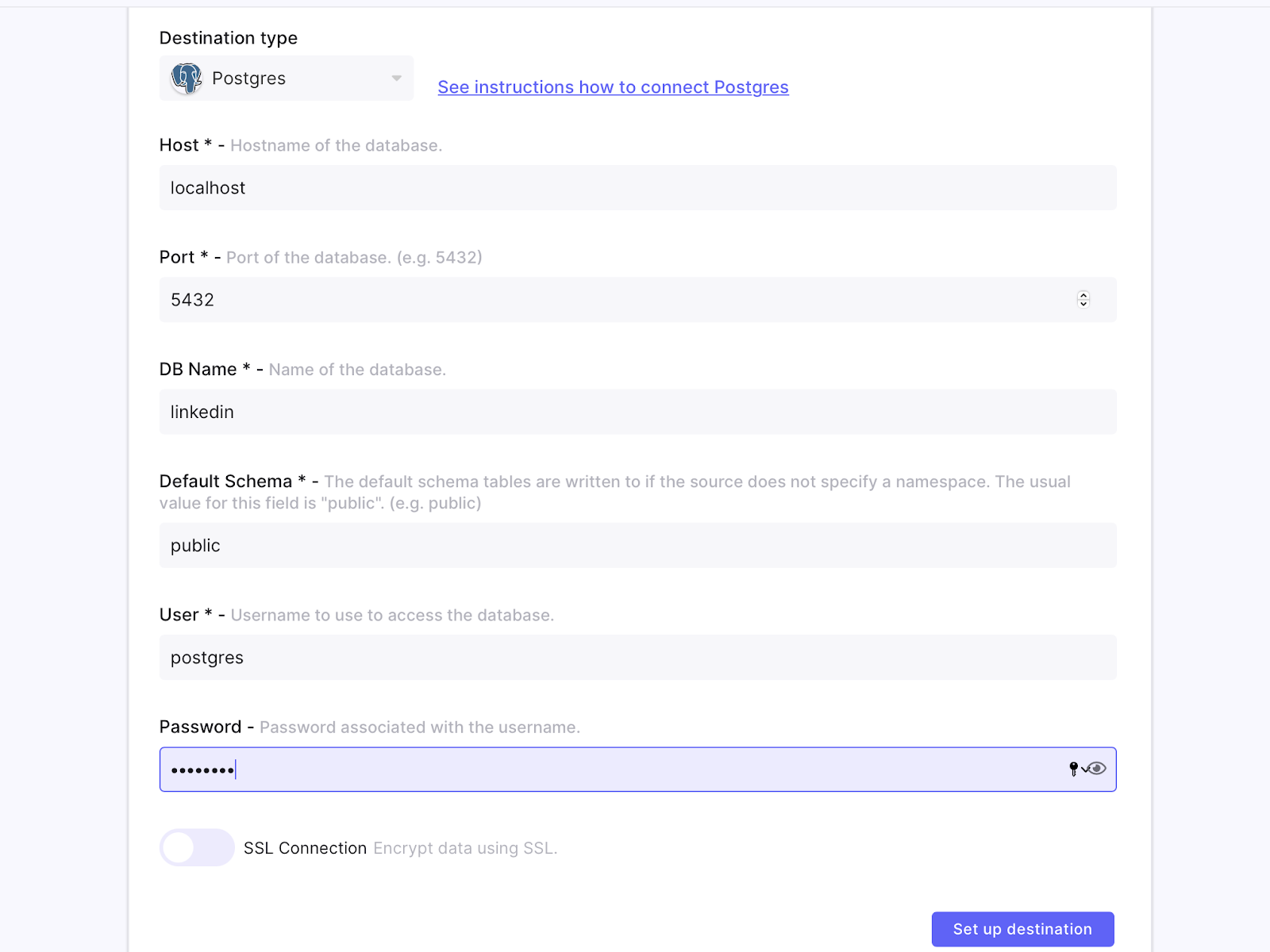
Before proceeding, ensure that the connection is successful.
Once the destination is set up, you can create the connection. Set the sync frequency to manual and the sync mode to append.
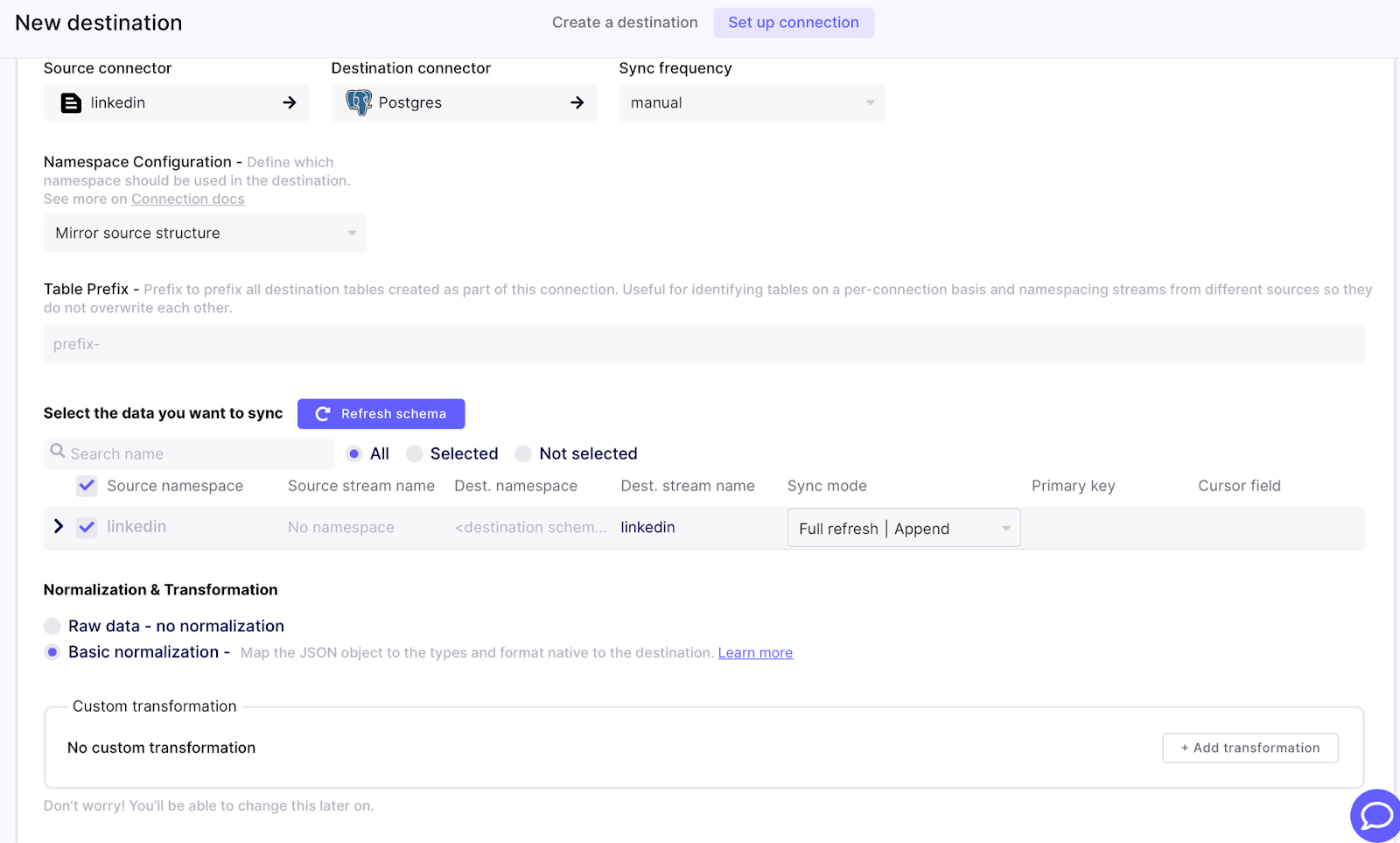
Once the connection is successfully set up, make a note of the connection ID which will be required for later for configuring Apache Airflow to trigger that connection. The ID can be found in the URL for that connection page.

The next step is to set up Apache Airflow so that it can trigger the Airbyte API endpoints.
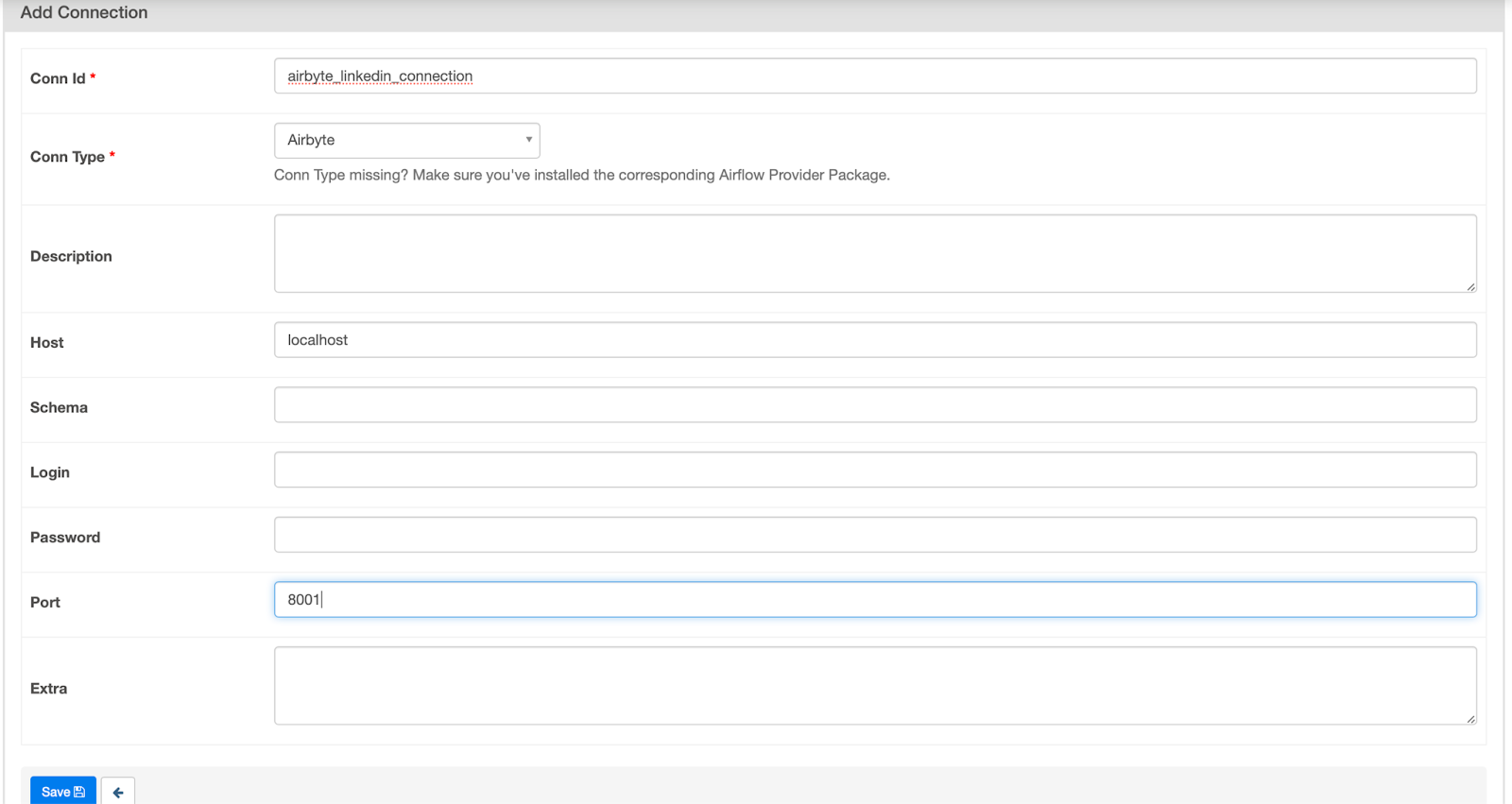
First go to Admin > Connection > Add Connection.
Give the connection ID a name (like airbyte_linkedin_connection in our case) and select Airbyte as the connection type. Enter localhost for host and 8001 for the port. Hit Save.
Now that the Airflow connection to trigger Airbyte is set up, we need to create a DAG inside Airflow that upon execution will run our python scraper, store the data in the JSON file and then trigger the Airbyte sync.
Create a dags folder and the dag file by running the following commands in your terminal. Airflow will automatically pick up the dag created in the folder upon restart.
To figure out which Linkedin profiles to scrape, the script needs a simple CSV file that contains the URLs to the required profiles as shown. Create a csv file with the following data on your local machine. More profiles can easily be added to the bottom of this file. Keep track of the location of this file since it is needed by the python script.
person_id,profile_url
1,https://www.linkedin.com/in/micheltricot/
2,https://www.linkedin.com/in/jean-lafleur-294083185/
3,https://www.linkedin.com/in/jrhizor/
Download Chrome driver and keep track of its location on your file system. This is an open source tool for automated testing of web apps across many browsers, and in this case we will use it for accessing LinkedIn programmatically in our Python web scraper.
Next copy the following into a file called airbyte_airflow_dag.py. Make sure to update the highlighted values.
Once the file is saved, restart the airflow webserver and scheduler and login to the Airflow UI again.
Once logged in, the newly added DAG should be visible. The DAG is scheduled to be run once a day but can also be triggered manually.
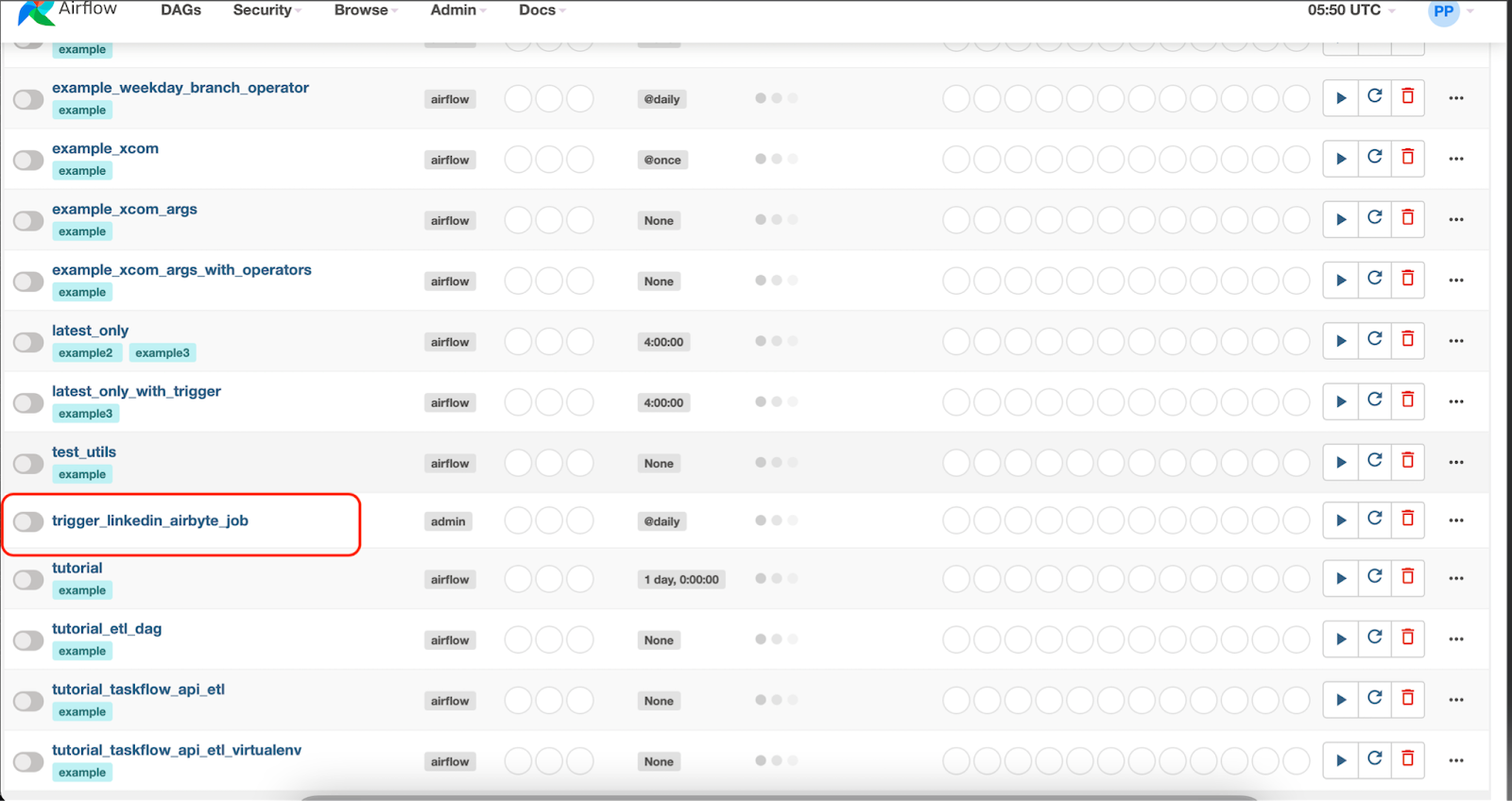
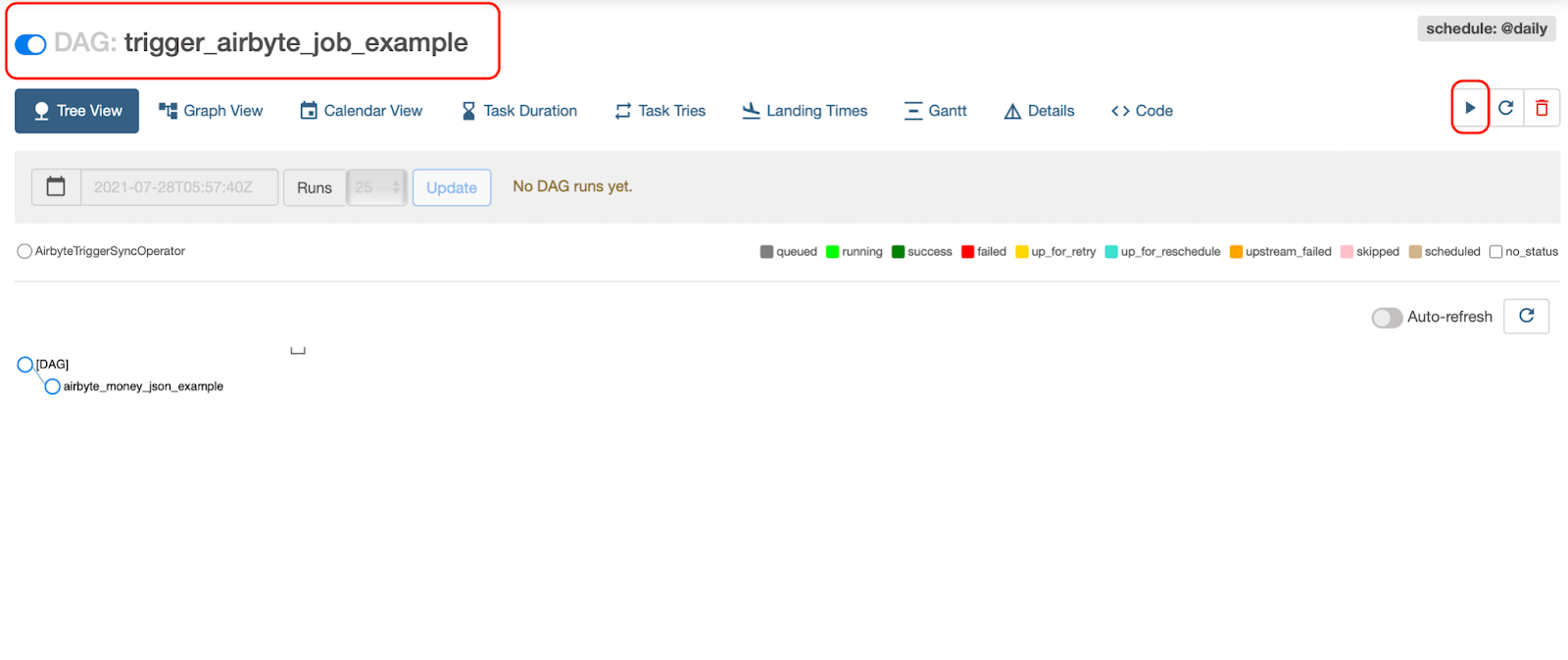
Click on the DAG to open up the DAG page. Here turn on the DAG and click on Play Button > Trigger DAG. This will begin the LinkedIn scraping.
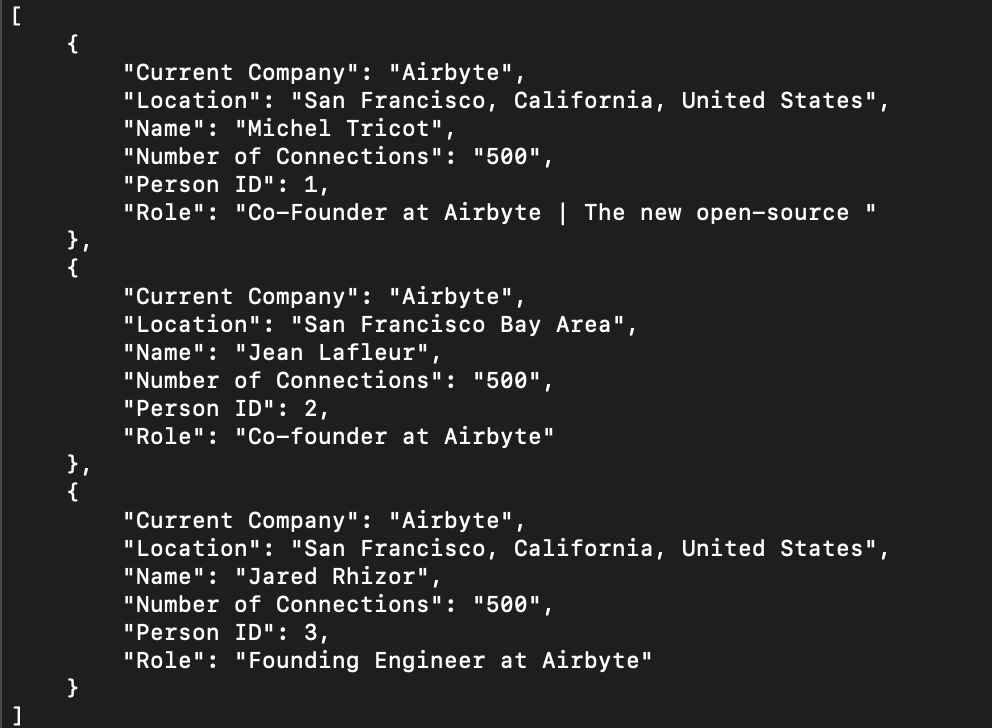
During the scraping the script will write data into the /tmp/airbyte_local/linkedin/linkedin.json and should look something like this.
Once the scraping is complete, it will trigger the Airbyte sync.
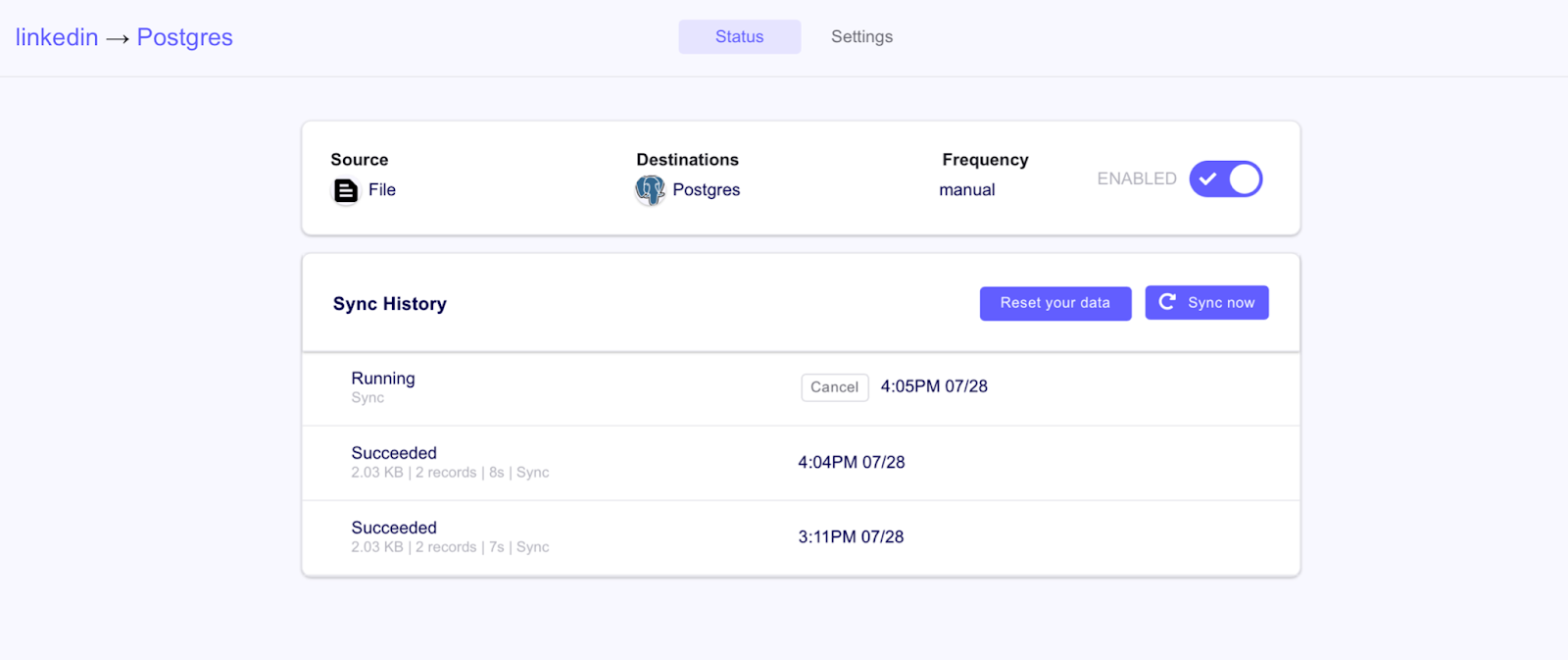
Once the sync is complete, you can verify that the Airflow job ran successfully in the UI.

You can view the tables created by Airbyte by running the following commands:
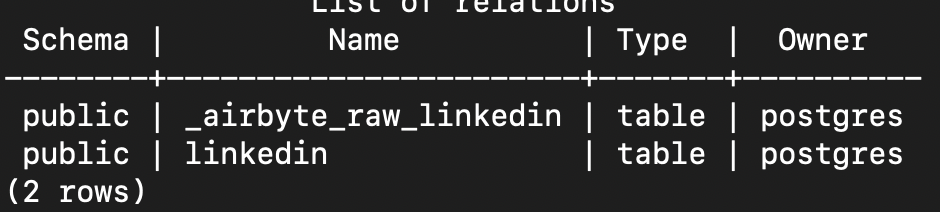
You can view the data imported to the table by running the following SQL table query on the linked table in postgreSQL

By querying this data, marketing campaigns can be executed to raise awareness for a new product feature based on job titles.
Here’s what we’ve accomplished during this recipe:
This was just one example of how Apache Airflow along with Airbyte can be used to create robust and complex workflows using open source tools.
We know that development and operations teams working on fast-moving projects with tight timelines need quick answers to their questions from developers who are actively developing Airbyte. They also want to share their learnings with experienced community members who have “been there and done that.”
Join the conversation at Airbyte’s community Slack Channel to share your ideas with over 1000 data engineers and help make everyone’s project a success.
Good luck, and we wish you all the best using Airbyte!


Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.


Learn how to easily export Postgres data to CSV, JSON, Parquet, and Avro file formats stored in AWS S3.

Set up Postgres CDC (Change Data Capture) in minutes using Airbyte, leveraging Debezium to build a near real-time EL(T).

Learn to replicate data from Postgres to Snowflake with Airbyte, and compare replicated data with data-diff.