No items found.
Set up a modern data stack with Docker
Learn how to quickly set up a modern data stack using Docker Compose with Airbyte, BigQuery, dbt, Airflow and Superset.


Learn how to quickly set up a modern data stack using Docker Compose with Airbyte, BigQuery, dbt, Airflow and Superset.
Today data is the most valuable resource of any business. But to be useful, it needs to be gathered, transformed and visualized. Every stage of the data pipeline needs to be as efficient and cost-effective as possible.
Over the past few years, many tools have emerged that apply to each stage of the data pipeline. A modern data stack is a suite of data tools that reduce the complexity to create a data pipeline. These tools include but are not limited to:
1. A data integration tool like Airbyte
2. A data warehouse like Google BigQuery or Snowflake
3. A data transformation tool like dbt or Dataform
4. A business intelligence tool like Superset or Metabase
In this tutorial, I demonstrate how to use Docker Compose to quickly set up a modern data stack using Airbyte, BigQuery, dbt, Airflow, and Superset. The pipeline uses Airbyte to read a CSV file into BigQuery, transform the data with dbt and visualize the data with Superset. Finally, you’ll use Airflow to schedule a daily job to sync the data from the source. Apart from BigQuery, all the other tools are open source.

Before we set up the project, let’s briefly look at each tool used in this example of a modern data stack to make sure you understand their responsibilities.
Airbyte is an open-source data integration tool. With Airbyte, you can set up a data pipeline in minutes thanks to its extensive collection of pre-built connectors. Airbyte can replicate data from applications, APIs, and databases into data warehouses and data lakes. Airbyte offers a self-hosted option with Docker Compose that you can run locally. In this modern data stack example, Airbyte is used to replicate data from a CSV file to BigQuery.
Google BigQuery is a highly scalable data warehouse. It features a columnar data structure and can query a large volume of data very quickly. In this modern data stack example, BigQuery works as the data store.
dbt is an open-source data transformation tool that relies on SQL to build production-grade data pipelines. dbt replaces the usual boilerplate DDL/DML required to transform data with simple modular SQL SELECT statements and handles dependency management. dbt provides a cloud-hosted option and a CLI, a Python API and integration with Airflow. In this modern data stack example, dbt applies a simple transformation on the ingested data using a SQL query. Airbyte's native integration with dbt is used to run the transformations.
Apache Airflow is an open-source data orchestration tool. Airflow offers the ability to develop, monitor, and schedule workflows programmatically. Airflow pipelines are defined in Python, which are then converted into Directed Acyclic Graphs (DAG). Airflow offers numerous integrations with third-party tools, including the Airbyte Airflow Operator and can be run locally using Docker Compose. Airflow is used in this modern data stack example to schedule a daily job that triggers the Airbyte sync, followed by the dbt transformation.
Apache Superset is a modern business intelligence, data exploration and visualization platform. Superset connects with a variety of databases and provides an intuitive interface for visualizing datasets. It offers a wide choice of visualizations as well as a no-code visualization builder. You can run Superset locally with Docker Compose or in the cloud using Preset. Superset sits at the end of this modern data stack example and is used to visualize the data stored in BigQuery.
To follow along, you need to:
1. Create a GCP account. If you do not have an account already, you can sign up for one for free. Once you have a GCP account and either provide a project ID or note down the auto-generated ID. I will be using modern-data-stack-demo as the project ID throughout this tutorial. Next, install the gcloud command line tool and use it to log in to your account and select the project you just created. You also need to enable billing for this project.
2. Install Docker and Docker Compose in your machine. You can follow this guide to install Docker and this one to install Docker Compose.
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.

This tutorial uses Docker Compose and a shell script to set up the required resources. Docker saves you from installing additional dependencies locall. You can quickly start and stop the instances. I have created a GitHub repo consisting of the compose files and a shell script, which you can clone.
The shell script setup.sh provides two commands, up and down, to start and stop the instances. The compose files are stored in docker-compose-airbyte.yaml, docker-compose-airflow.yaml, and superset/docker-compose-superset.yaml. You can go through these files and make any necessary customization, for example, changing the ports where the instances start or installing additional dependencies.
BigQuery is the heart and soul of the data stack, so you need to configure it first. Sign in to your Google Cloud Console Dashboard and select the project you created. Navigate to the BigQuery page from the sidebar. You should see a project automatically created for you on the SQL Workspace page. Then create a dataset. I chose the name demo_dataset. Next, select a location for this dataset and note it down.
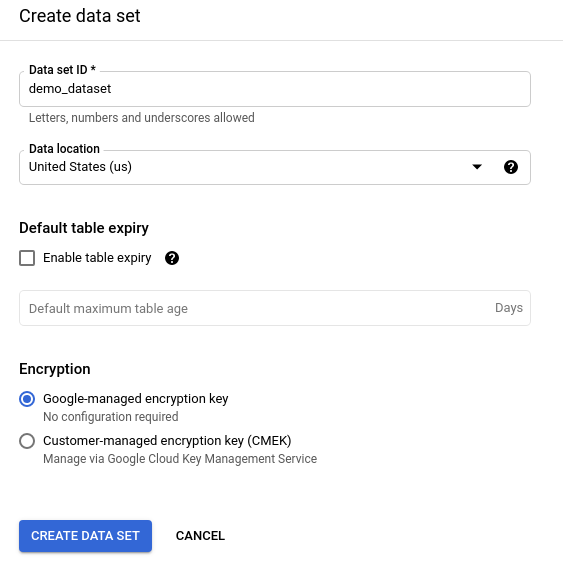
The different components that connect to BigQuery need access to the dataset you just created. For that, you need to create a service account and give access to BigQuery. You can do that manually through the UI or use the gcloud auth login command to do that for you. Then you need to set up the project with gcloud config set project PROJECT_ID with your own project ID. Assuming you have logged in to the project, you can run the following commands in bash.
These commands create a service account named bigquery-sa and add BigQuery User and BigQuery Data Editor permissions to it. It then creates a key and downloads it to your local machine as bigquery-sa.json.
With BigQuery set up, you’re ready to use Docker Compose to spin up Airflow, Airbyte and Superset instances.
First, in the GitHub repo, run the following command.
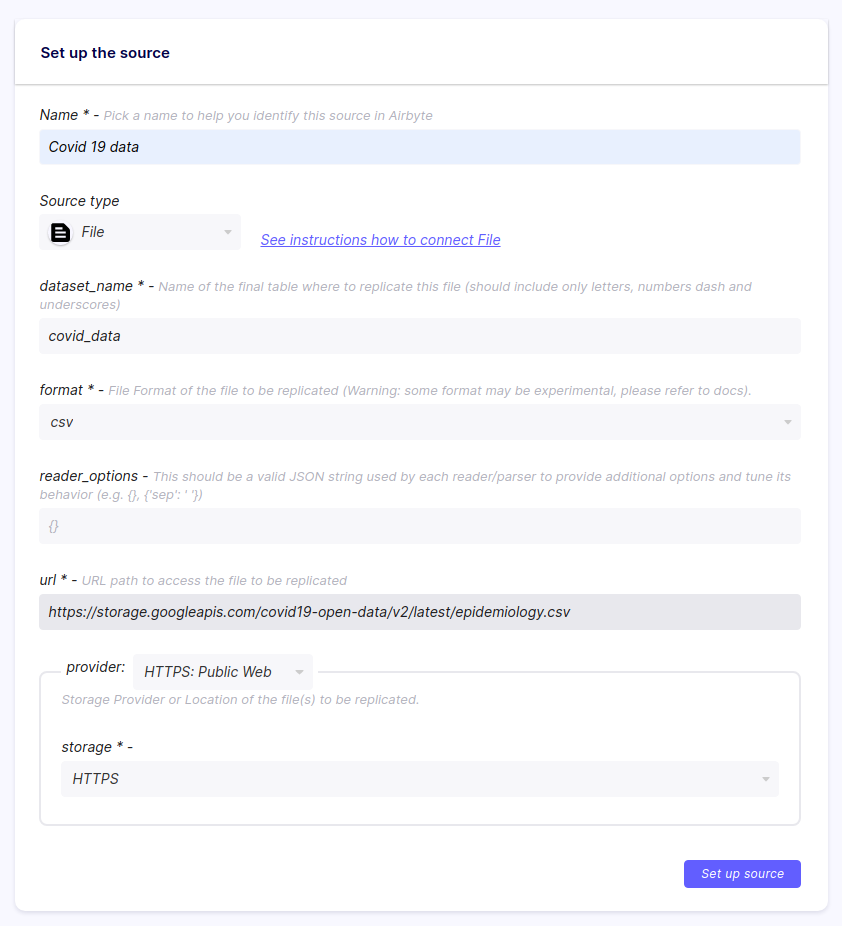
The script launches the Airbyte instance at http://localhost:8000. In this tutorial, you will use the File source to read a CSV file. Enter Covid 19 data as the source name, and select File as the source type. Make sure csv is chosen as the format and paste the following URL in the url field: https://storage.googleapis.com/covid19-open-data/v2/latest/epidemiology.csv. Finally, enter the name of the dataset you created in BigQuery.
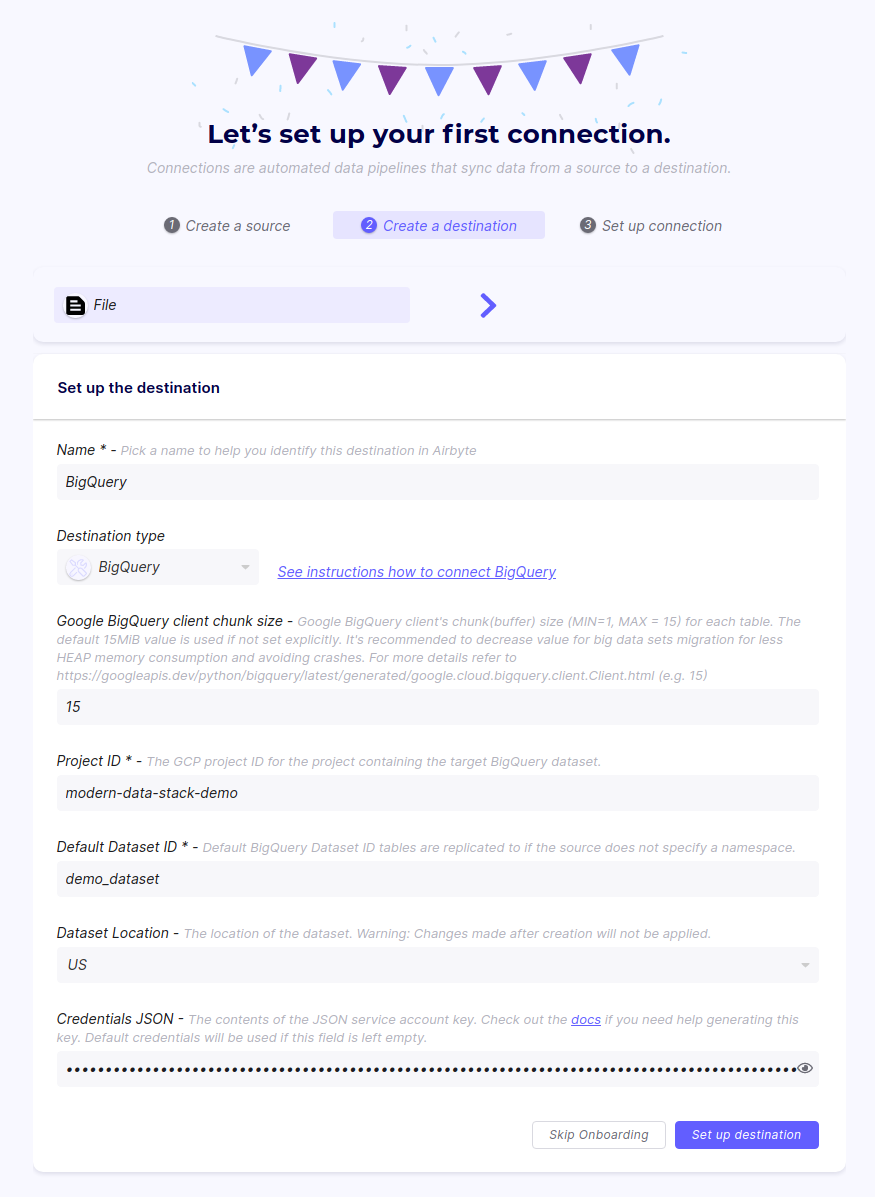
Enter BigQuery as the destination name on the next page and select BigQuery as the destination type. Enter the GCP project ID and your dataset ID. Finally, paste the content of the service account key file.
Set the sync frequency to Manual, the sync mode to Full refresh | Append and select Basic Normalization. Then under the Custom Transformation section, add a custom dbt transformation.
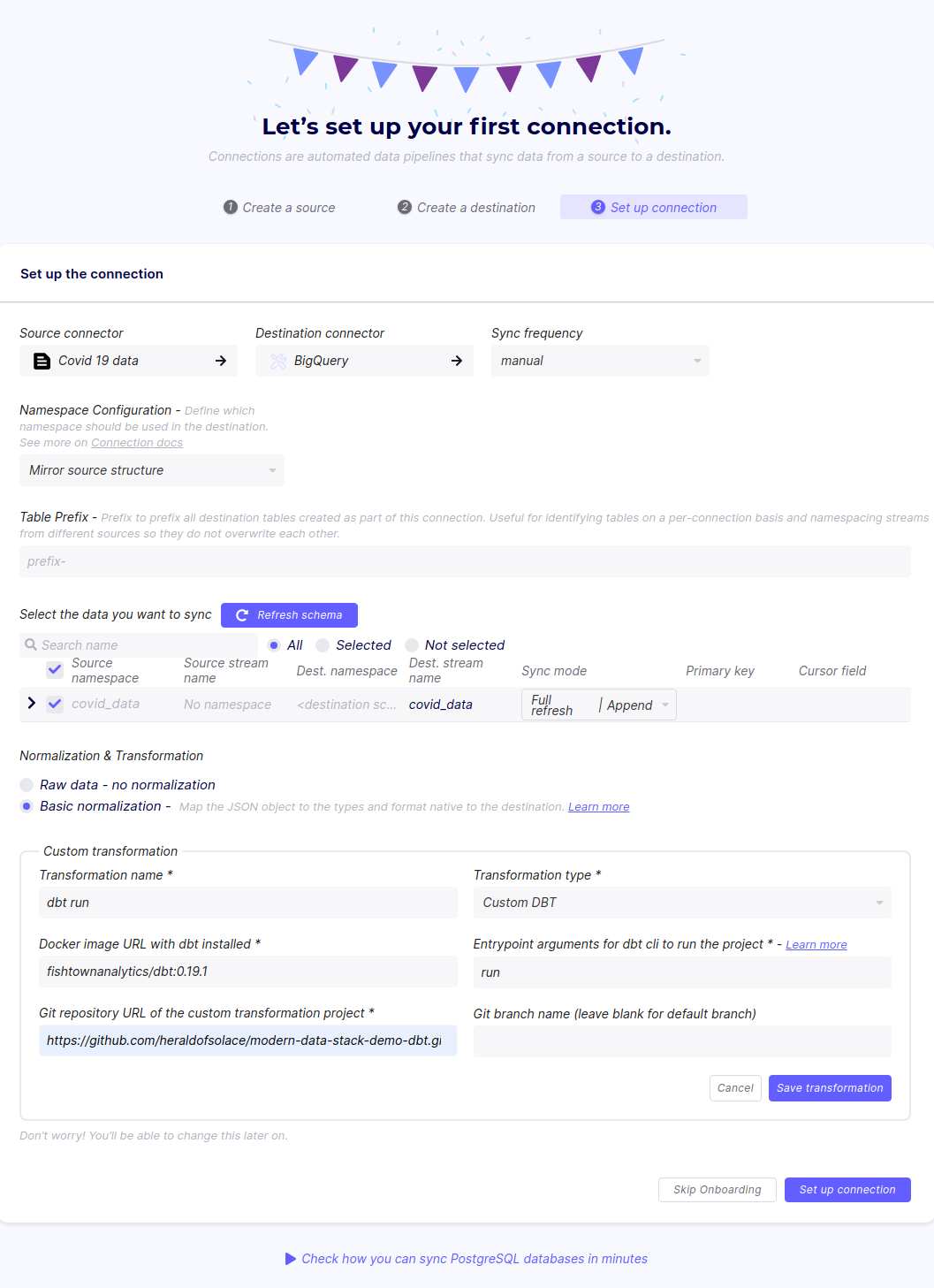
Enter the URL of your Gitbub dbt repository. I used this Github repo, which contains one model in models/cases.sql to creates a simple view of the records where new_recovered is greater than new_confirmed.
Once you have setup the connection, you need to save the connection ID from the URL to later use it integrate with Airflow on your command line when running the setup.sh command.
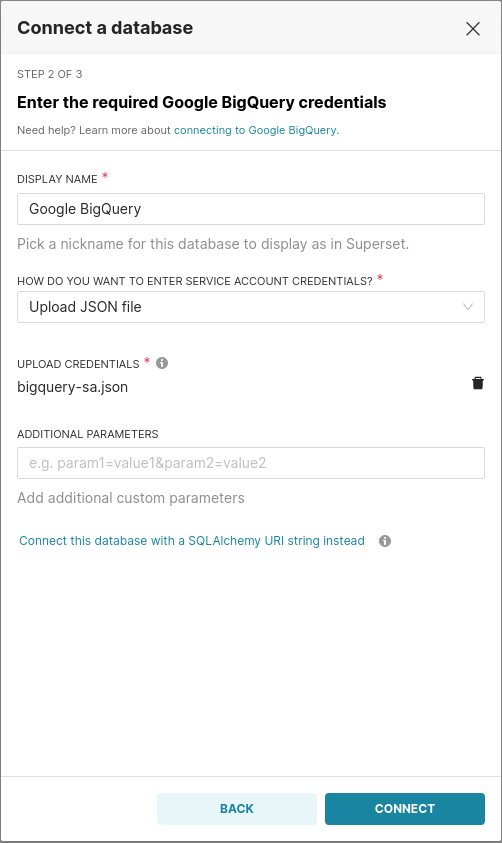
Once the setup.sh command has completed, visit http://localhost:8088 to access the Superset UI. Enter admin as username and password. Choose Google BigQuery from the supported databases drop-down. Then upload the service account keyfile.
Once the modern data stack is ready and running, you can start using it to process your data.
A DAG has already been created in Airflow from the file dags/dag_airbyte_dbt.py. It schedules a daily job that first runs Airbyte to sync the data. Airbyte is also responsible for running the dbt transformations. Visit http://localhost:8080 to access the Airflow UI. Use airflow as both the username and password.
You should be presented with a list of example DAGs as well as trigger_airbyte_dbt_job. Simply enable the DAG, and it should start running.

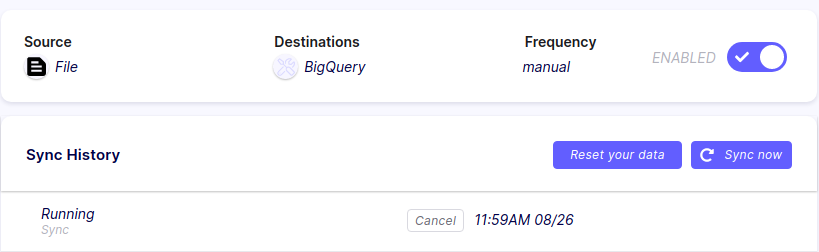
Once the DAG is running, you can verify that the sync has started in the Airbyte UI. Depending on the size of the source, it might take a few minutes.
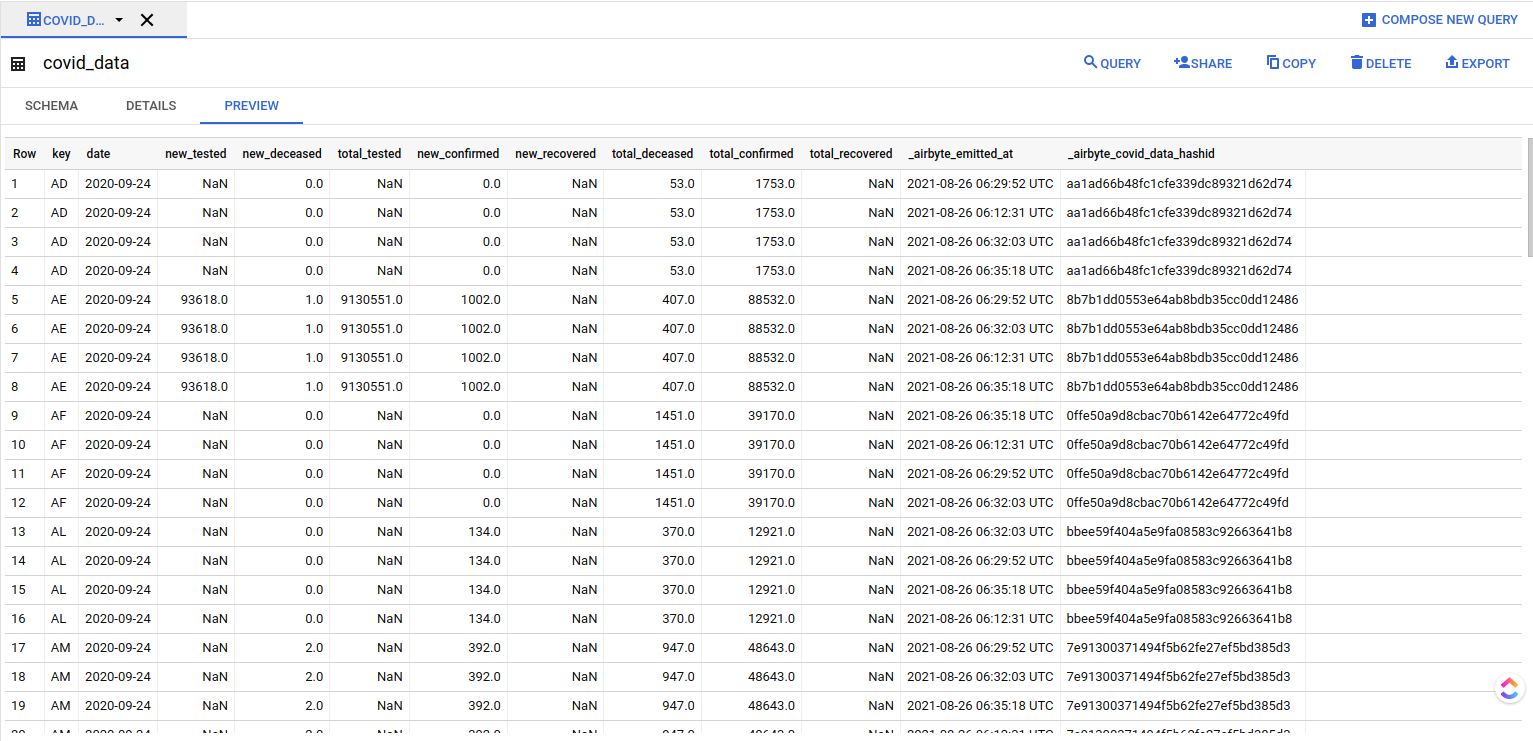
Once finished, your BigQuery interface should show the following structure:

The _airbyte_raw_covid_data table contains the raw JSON emitted by Airbyte, which is then normalized to form the covid_data table. The cases view corresponds to the dbt model. You can take a look at the preview tab to get an idea of the covid_data table structure.
You can check that the `cases` view contains the SQL query that you had in cases.sql file in the dbt repository.
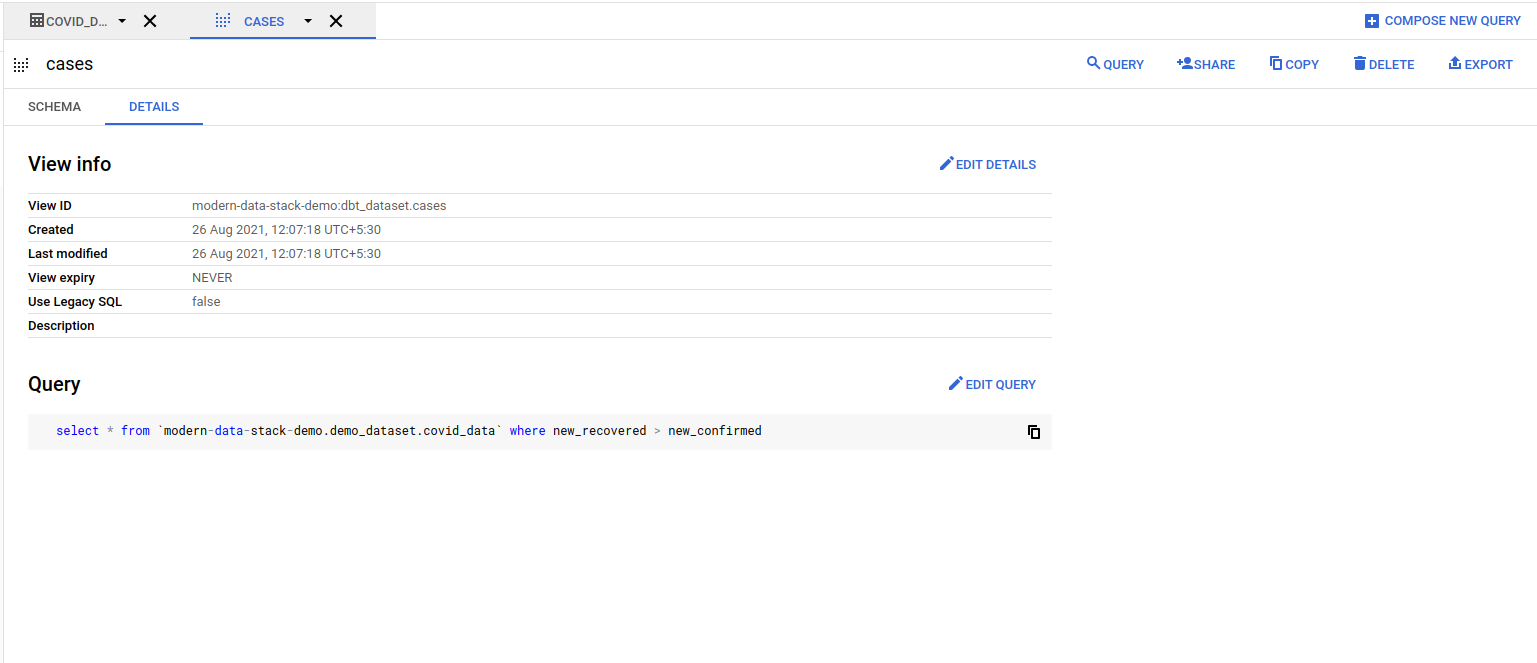
Once Airbyte has loaded the query into BigQuery, you can add it as a dataset in Superset and start visualizing the data. First, navigate to the Dataset page. Select the BigQuery connection you created earlier as the database, demo_dataset as the schema and cases as the table schema.
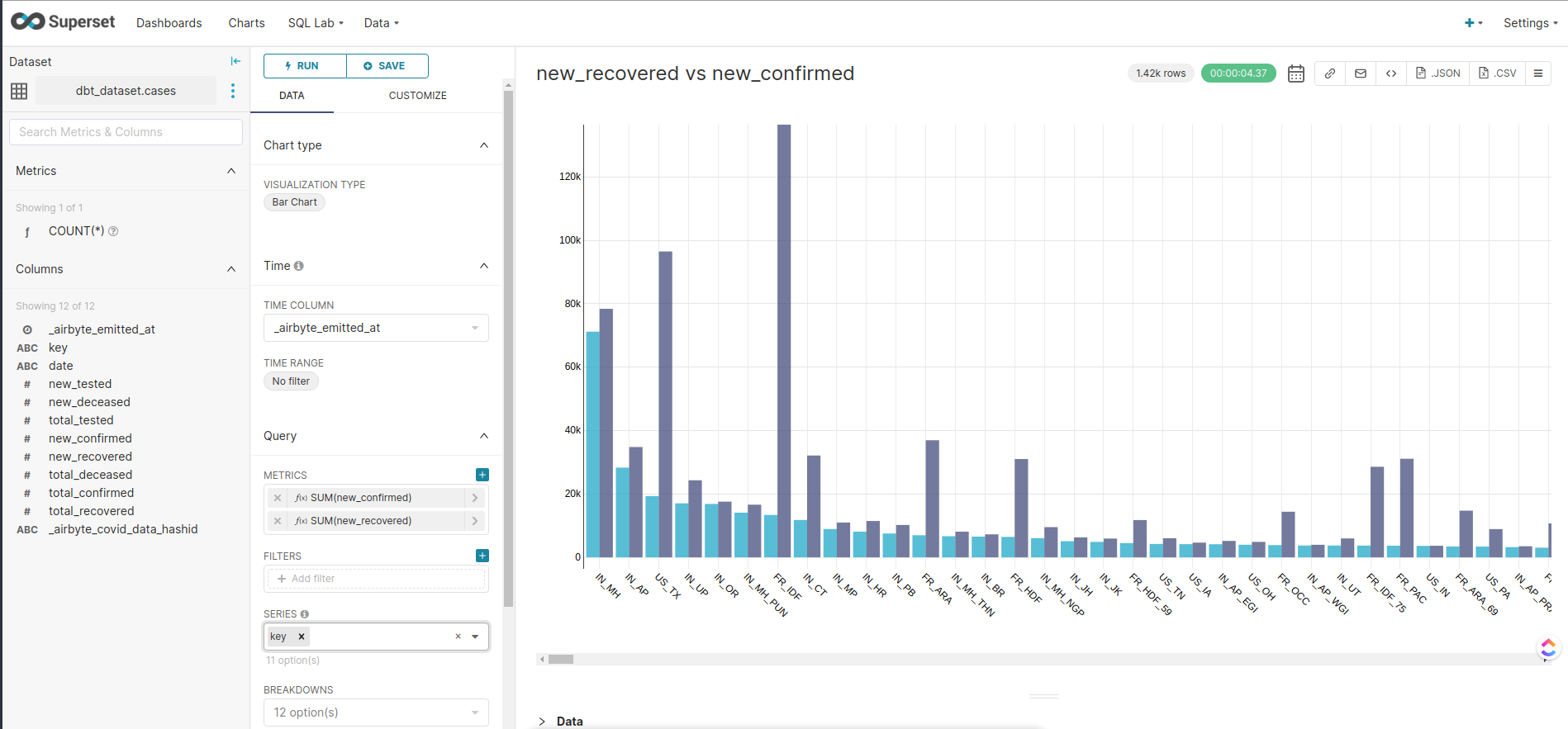
Now you can create a new chart using the data stored in BigQuery. Navigate to the Charts tab, choose cases as the dataset and choose a chart type. I chose the bar chart. On the next page, you can add the metrics you want to visualize. In this case, I chose simply the sum of new_recovered and the sum of new_confirmed, organized by the key.
You can clean up the resources by running the following command.
Using a modern data stack can speed up your data pipeline drastically and save you hours of manual labor. Using self-hosted open source tools like Airbyte, Airflow, dbt, and Superset ensures that the components are running within your own infrastructure. All these projects provide Docker Compose files that make it easy to set them up locally. If you wish to deploy a scalable modern data stack to the cloud, you can use Terraform and Kubernetes to automate the process.
Aniket Bhattacharyea is a student doing a Master's in Mathematics and has a passion for computers and software. He likes to explore various areas related to coding and works as a web developer using Ruby on Rails and Vue.


Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.


Use Octavia CLI to import, edit, and apply Airbyte application configurations to replicate data from Postgres to BigQuery.
.png)
Learn how to quickly set up a modern data stack using Docker Compose with Airbyte, BigQuery, dbt, Airflow and Superset.
Learn how to easily automate your LinkedIn Scraping with Airflow and Beautiful Soup.