Data Warehouse vs. Operational Database! What? How? Which One?

What is a data warehouse
In this section I discuss what a data warehouse is, give an example of the kind of workload that data warehouses are designed to be used for, and show how data is stored in a column-oriented format on disk to efficiently satisfy the expected workload.
A brief definition of a data warehouse
As is the case for an operational database, a data warehouse is also a storage technology in which data is (often) stored as a structured collection of tables that are conceptually organized as rows and columns. Because of the similarities with databases, data warehouses are sometimes referred to as OLAP databases.
Each row in a data warehouse represents a record. However, as opposed to operational databases, data warehouses are generally designed for OLAP (Online Analytical Processing) workloads which involve running a small number of large analytical operations. These analytics operations often only require data from a subset of the available columns, but they may need most (or all) of the values within the relevant columns.
Examples of popular data warehouses are BigQuery, Redshift, and IBM Db2 Warehouse.
An example data warehouse workload
Using the same data presented in the database example above, a table stored in a data warehouse looks the same – but an important difference is how the data is stored on disk. The different colors represent the values in each column that will be stored side-by-side on disk. This will be discussed in more detail below, when the disk layout is covered.
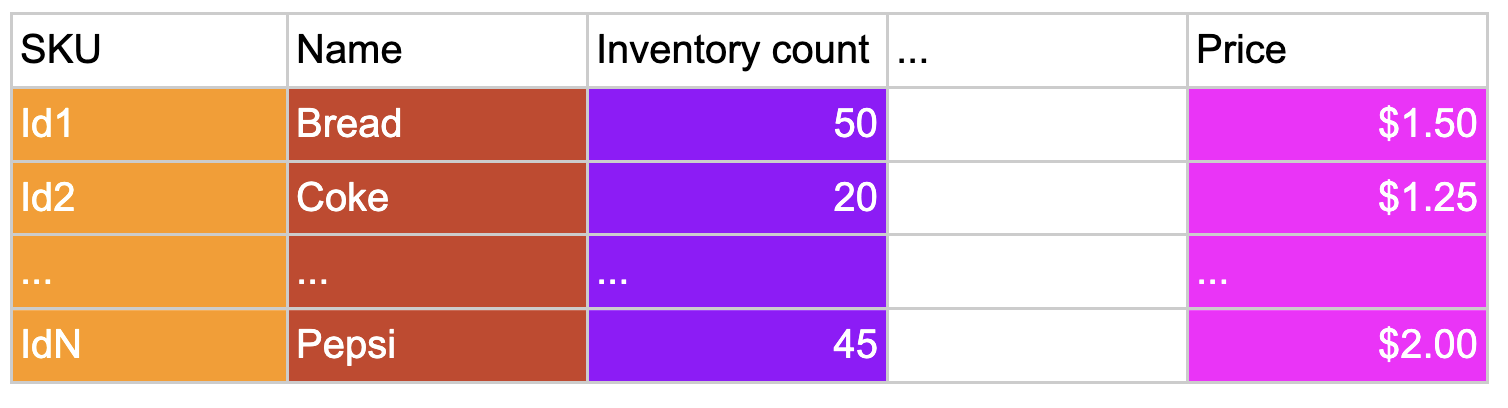
A data warehouse is optimized for analytics operations, such as efficiently finding the average price of every product in inventory. Such an operation would need to load all of the prices from disk into memory and process all of these prices in order to compute the average. Data warehouses are designed to efficiently load data for one or more columns from disk into memory, and to efficiently process a large number of values from within each column.
Data warehouse storage
In a traditional row-oriented operational data store, entire rows of data must be read even if a particular query requests data from only a few columns.
On the other hand, data warehouses often store their data in a column-oriented manner which means that the values contained in a given column are stored together on disk. Storing the data in this manner corresponds to the most common data access and usage patterns associated with OLAP workloads, such as the calculation of the average price across all products that was just discussed.
Storing data in this manner minimizes the number of pages that need to be read from disk when performing OLAP operations. The column-oriented storage of data is one of the key architectural differences of data warehouses versus operational databases, and is a big reason why analytics operations, which often retrieve and process many values within a given column, are super efficient in data warehouses. As should be clear from the latency numbers discussed earlier, keeping disk activity to a minimum is a key factor for providing good performance.
Assuming that data is stored on a solid-state drive (SSD), data warehouses often logically store their data in a column-oriented format, such as the following:

And if a data warehouse is using spinning disks, the data storage may look as follows:

More about column-oriented data
Column-oriented data storage is a large factor in the ability of data warehouses to efficiently process OLAP workloads. In addition to reducing the amount of disk operations, other benefits of column-oriented storage are improved data compression and the ability to leverage parallel processing. Because of these advantages, several open source column-oriented storage formats have appeared.
Data compression
Each column contiguously stores a single type of data, which means that data warehouses can efficiently leverage various data compression techniques. Compressing data not only reduces storage costs, it can improve performance by reducing the number of disk operations.
Columnar-vectorized processing
The column-oriented storage format used by data warehouses allows them to efficiently leverage modern SIMD (Single Instruction Multiple Data) computer architectures for columnar-vectorized processing. In this kind of processing, a batch of values (a “vector”) are processed in parallel in a single operation, which accelerates processing of OLAP workloads.
Open column-oriented data formats
Because of the benefits of column-oriented data storage for OLAP workloads, several open formats have appeared. These include:
OLTP database performance versus OLAP data warehouse performance
While it is difficult to provide a generic and universally accurate comparison of the performance of data warehouses versus operational databases, it is possible to find comparisons of specific systems. For example, a paper called SQLite: Past, Present, and Future has been published which compares SQLite (an in-process/embedded OLTP database) versus DuckDB (an in-process/embedded OLAP data warehouse). The conclusion of this paper is the following:
- SQLite out-performs DuckDB on a write transactions benchmark by 10x-500x on a powerful cloud server and 2x-60x on a Raspberry Pi, for small to large databases.
- For analytical benchmarks using the SSB (Star Schema Benchmark) DuckDB out-performs SQLite by up to 30-50x and as low as 3-8x.
These results confirm what you would expect to see: DuckDB (OLAP) does well when performing analytics operations, and SQLite (OLTP) performs well for transactional workloads.
Do you need an operational database or a data warehouse?
As you have just seen, OLTP databases are good at some workloads, and OLAP data warehouses are good for other workloads. Below I summarize the factors that will help you determine if you should use an operational database or a data warehouse. I also briefly touch on the possibility that neither of these technologies may be suitable for your data requirements.
When to use an operational database?
Operational databases are designed for OLTP (online transaction process) workloads including the following:
- Thousands simultaneous users
- Small, atomic transactions
- Reliability – often designed as an operational systems that acts as the source of truth
- Realtime fast and efficient CRUD operations (create, read, update, and delete)
- Efficient data storage
- Storing current data – may make historical analysis impossible
When to use a data warehouse?
Data warehouses are good for OLAP (online analytical processing) workloads such as the following:
- A small number of users, each of which may execute heavy analytics workloads
- Deep analysis with complex queries across large data sets
- Downtime is permitted – generally not used as the one-and-only operational system
- Denormalized (duplicate) data in order to improve the efficiency of analytics operations
- Storing of historical data for deeper insights
To learn more, you can also check out our article comparing Data Warehouse vs Database to understand their scope and purpose in-depth!
Do you want the benefits of both an operational database and a data warehouse?
You may have read through the above lists and thought “I want to support both transactional and analytics workloads! ” – if so, you may wish to run a data warehouse and an operational database side-by-side. In this case you will need a way to keep the data synchronized between your operational database and your data warehouse, this is discussed later in this article.
Do you need something totally different?
If you need to store huge amounts of unstructured data, then you may be dealing with data that doesn’t fit well into either a row-oriented operational database or into a column-oriented data warehouse. In this case, you may consider storing your data in a data lake or a lakehouse. These alternatives will be discussed in more detail in a future article.
How can you sync data between an operational database and a data warehouse?
If you have decided that you require both a data warehouse and an operational database in order to efficiently handle both OLAP and OLTP workloads, you will want to synchronize data from your operational database into your data warehouse. This can be achieved with ELT tools such as Airbyte, which are designed for database replication into data warehouses! A few examples of replicating data from databases into data warehouses can be found in the tutorials section of Airbyte’s website, which includes tutorials such as the following:
- MySQL to BigQuery
- Postgres to Redshift
- Microsoft SQL to Snowflake
- Postgres to BigQuery
- Microsoft SQL to Redshift
- And many more!
Conclusion
In this article you have learned the fundamental difference between data warehouses and operational databases. This included an overview of the underlying architectural differences between these technologies, and how they are optimized for different workloads. You have also seen why it may be beneficial to run both an operational database and a data warehouse side-by-side. If this is your case, then you can make use of a data integration tool such as Airbyte to handle the synchronization of data between these systems.
I briefly touched on the possibility that neither an operational database nor a data warehouse is the right choice for your data storage – in some cases a data lake or a lakehouse is a more appropriate technology choice. Keep your eye on Airbyte’s blog for a discussion about these alternatives in a future article.
If you are looking to dive deeper into Airbyte, you may be interested in Airbyte tutorials or Airbyte’s blog. You may also consider joining the conversation on our community Slack Channel, participating in discussions on Airbyte’s discourse, or signing up for our newsletter.