Implement AI data pipelines with Langchain, Airbyte, and Dagster
Learn how to set up a maintainable and scalable pipeline for integrating diverse data sources into large language models using Airbyte, Dagster, and LangChain.


Learn how to set up a maintainable and scalable pipeline for integrating diverse data sources into large language models using Airbyte, Dagster, and LangChain.
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.




Large language models (LLMs) like ChatGPT are emerging as a powerful technology for various use cases, but they need the right contextual data. This data is located in a wide variety of sources - CRM systems, external services and a variety of databases and warehouses. Also, a stable pipeline is required to keep the data up to date - this is not a one-off job you can do with some shell/Python hacking.
Airbyte, as a data integration (ELT) platform, plays an essential role in this, as it makes it very easy to get data from just about every tool right in front of your LLM. When combined with an orchestrator like Dagster and a framework like LangChain, making data accessible to LLMs like GPT becomes easy, maintainable and scalable.
This article explains how you can set up such a pipeline.
Set up your connection in Airbyte to fetch the relevant data (choose from hundreds of data sources or implement your own):

Use Dagster to set up a pipeline that processes the data loaded by Airbyte and stores it in a vector store
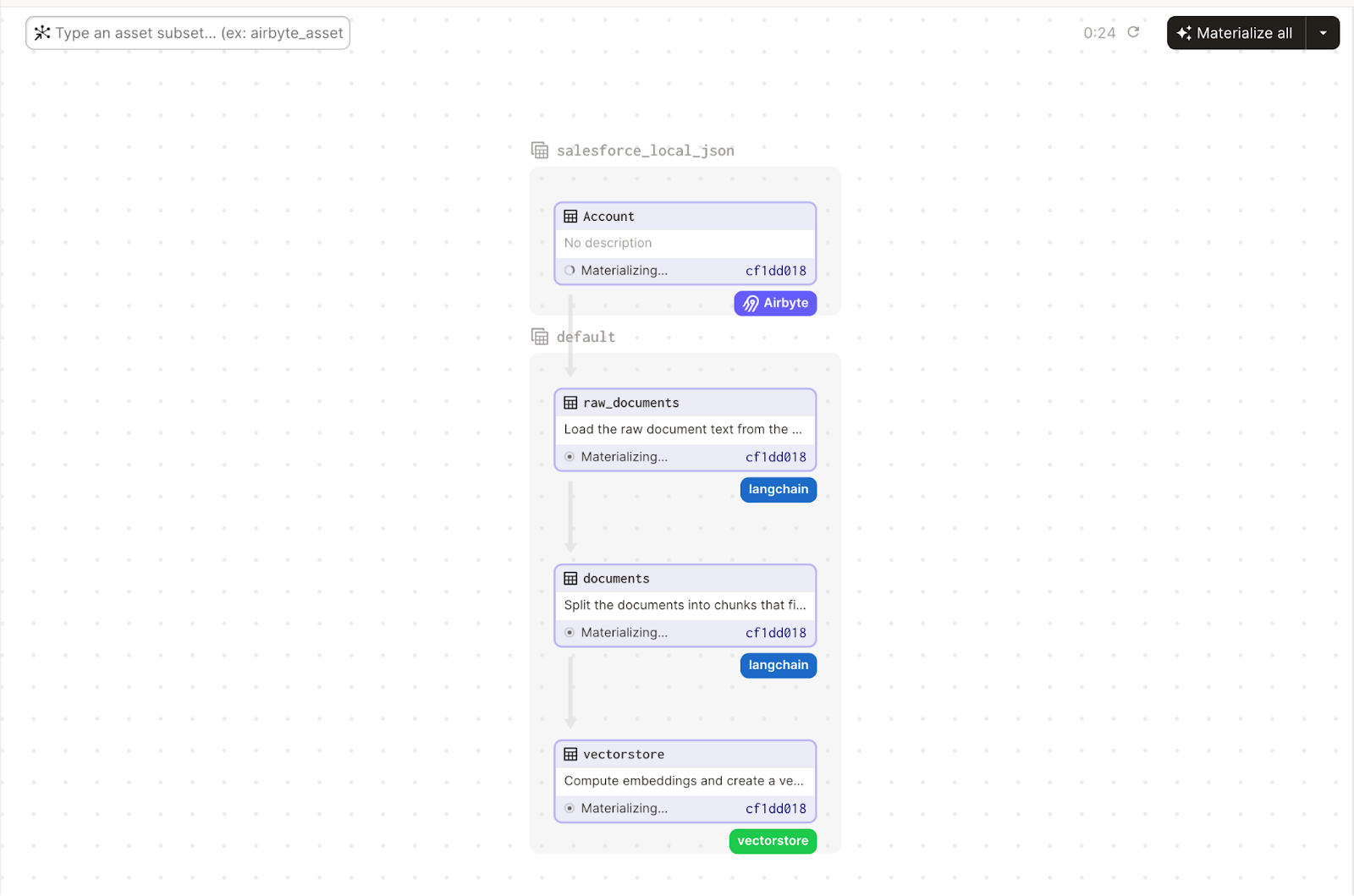
Combine contextual information in the vectorstore with LLMs using the LangChain retrieval Question/Answering (QA) module:

The final code for this example can be found on Github.
To run, you need:
Install a bunch of Python dependencies we’ll need to go forward:
First, start Airbyte locally, as described on https://github.com/airbytehq/airbyte#quick-start.
Set up a connection:

Configure the software-defined assets for dagster in a new file ingest.py:
First, load the existing Airbyte connection as Dagster asset (no need to define manually). The load_assets_from_airbyte_instance function will use the API to fetch existing connections from your Airbyte instance and make them available as assets that can be specified as dependencies to the python-defined assets processing the records in the subsequent steps.
Then, add the LangChain loader to turn the raw jsonl file into LangChain documents as a dependent asset (set stream_name to the name of the stream of records in Airbyte you want to make accessible to the LLM - in my case it’s Account):
Then, add another step to the pipeline splitting the documents up into chunks so they will fit the LLM context later:
The next step generates the embeddings for the documents:
Finally, define how to manage IO (for this example just dumping the file to local disk) and export the definitions for Dagster:
See the full ingest.py file here
Now, we can run the pipeline:
Alternatively, you can materialize the Dagster assets directly from the command line using:
The next step is to put it to work by running a QA chain using LLMs:
To do this, create a new file query.py.
Load the embeddings:
Initialize LLM and QA retrieval chain based on the vectorstore:
Add a question-answering loop as the interface:
See the full query.py file here
You can run the QA bot with:
When asking questions about your use case (e.g. CRM data), LangChain will manage the interaction between the LLM and the vector store:
This is just a simplistic demo, but it showcases how to use Airbyte and Dagster to bring data into a format that can be used by LangChain.
From this core use case, there are a lot of directions to explore further:
LangChain doesn’t stop at question answering - explore the LangChain documentation to learn about other use cases like summarization, information extraction and autonomous agents
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.


Set up Postgres CDC (Change Data Capture) in minutes using Airbyte, leveraging Debezium to build a near real-time EL(T).

Easily set up MySQL CDC using Airbyte, harnessing the power of a robust tool like Debezium to construct a near real-time ELT pipeline.
Learn how to create an Airflow DAG (directed acyclic graph) that triggers Airbyte synchronizations.