Airbyte, dbt, Snowflake and Looker (ADSL) Stack
Experience a full data stack with Airbyte, dbt, Snowflake, and Looker. Effortlessly move from data extraction to insightful analytics, all within one cohesive template.
Welcome to the "Airbyte-dbt-Snowflake-Looker Integration" repository! This repo provides a quickstart template for building a full data stack using Airbyte, Dagster, dbt, Snowflake and Looker. Easily extract data from Postgres and load it into Snowflake using Airbyte, and apply necessary transformations using dbt, all orchestrated seamlessly with Dagster. Then connect your Snowflake instance to Looker for business intelligence, analytics, data modeling, etc. While this template doesn't delve into specific data or transformations, its goal is to showcase the synergy of these tools.
This quickstart is designed to minimize setup hassles and propel you forward.
Infrastructure Layout
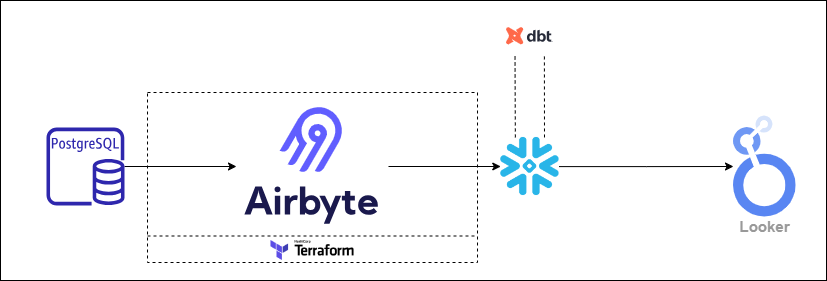
Pipeline DAG

Prerequisites
Before you embark on this integration, ensure you have the following set up and ready:
- Python 3.10 or later: If not installed, download and install it from Python's official website.
- Docker and Docker Compose (Docker Desktop): Install Docker following the official documentation for your specific OS.
- Airbyte OSS version: Deploy the open-source version of Airbyte. Follow the installation instructions from the Airbyte Documentation.
- Terraform: Terraform will help you provision and manage the Airbyte resources. If you haven't installed it, follow the official Terraform installation guide.
Setting an environment for your project
Get the project up and running on your local machine by following these steps:
1. Clone the repository (Clone only this quickstart):
2. Navigate to the directory:
3. Set Up a Virtual Environment:
For Linux & Mac:
For Windows:
4. Install Dependencies:
Setting Up Airbyte Connectors with Terraform
Airbyte allows you to create connectors for sources and destinations, facilitating data synchronization between various platforms. In this project, we're harnessing the power of Terraform to automate the creation of these connectors and the connections between them. Here's how you can set this up:
1. Navigate to the Airbyte Configuration Directory:
Change to the relevant directory containing the Terraform configuration for Airbyte:
2. Modify Configuration Files:
Within the infra/airbyte directory, you'll find three crucial Terraform files:
- provider.tf: Defines the Airbyte provider.
- main.tf: Contains the main configuration for creating Airbyte resources.
- variables.tf: Holds various variables, including credentials.
Adjust the configurations in these files to suit your project's needs. Specifically, provide credentials for your Postgres and Snowflake connections. You can utilize the variables.tf file to manage these credentials.
3. Initialize Terraform:
This step prepares Terraform to create the resources defined in your configuration files.
4. Review the Plan:
Before applying any changes, review the plan to understand what Terraform will do.
5. Apply Configuration:
After reviewing and confirming the plan, apply the Terraform configurations to create the necessary Airbyte resources.
6. Verify in Airbyte UI:
Once Terraform completes its tasks, navigate to the Airbyte UI. Here, you should see your source and destination connectors, as well as the connection between them, set up and ready to go.
Setting Up the dbt Project
dbt (data build tool) allows you to transform your data by writing, documenting, and executing SQL workflows. Setting up the dbt project requires specifying connection details for your data platform, in this case, Snowflake. Here’s a step-by-step guide to help you set this up:
1. Navigate to the dbt Project Directory:
Change to the directory containing the dbt configuration:
2. Update Connection Details:
You'll find a profiles.yml file within the directory. This file contains configurations for dbt to connect with your data platform. Update this file with your Snowflake connection details.
3. Utilize Environment Variables (Optional but Recommended):
To keep your credentials secure, you can leverage environment variables. An example is provided within the profiles.yml file.
4. Test the Connection:
Once you’ve updated the connection details, you can test the connection to your Snowflake instance using:
If everything is set up correctly, this command should report a successful connection to Snowflake.
Orchestrating with Dagster
Dagster is a modern data orchestrator designed to help you build, test, and monitor your data workflows. In this section, we'll walk you through setting up Dagster to oversee both the Airbyte and dbt workflows:
1. Navigate to the Orchestration Directory:
Switch to the directory containing the Dagster orchestration configurations:
2. Set Environment Variables:
Dagster requires certain environment variables to be set to interact with other tools like dbt and Airbyte. Set the following variables:
Note: The AIRBYTE_PASSWORD is set to password as a default for local Airbyte instances. If you've changed this during your Airbyte setup, ensure you use the appropriate password here.
3. Launch the Dagster UI:
With the environment variables in place, kick-start the Dagster UI:
4. Access Dagster in Your Browser:
Open your browser and navigate to http://127.0.0.1:3000. Here, you should see assets for both Airbyte and dbt. To get an overview of how these assets interrelate, click on "view global asset lineage". This will give you a clear picture of the data lineage, visualizing how data flows between the tools.
Integrating with Looker
Looker is a product that helps you explore, share, and visualize your company's data so that you can make better business decisions. It is an enterprise platform for BI, data applications, and embedded analytics that helps you explore and share insights in real time. It also has the ability to convert user input via a Graphical User Interface (GUI) into SQL queries and subsequently transmit them directly to the database in real-time. To get started with Looker and learn more about it, check here.
Follow the steps below to integrate your Snowflake instance with your Looker studio.
Create a Looker User in Snowflake
To allow Looker run queries in Snowflake, you need to create a dedicated user for the looker instance in Snowflake and provision access for the user. Run the queries below in Snowflake to do this.
You can add in the ON FUTURE keyword to persist GRANT statements for future tables and objects in the database to prevent re-running the GRANT statements as new tables are created.
Adding the Database Connection in Looker
After creating the looker user in snowflake, we need to create a connection from Looker to Snowflake using our Snowflake credentials and the looker user we just created in Snowflake. To do this, follow the steps below.
1. Navigate to the Admin panel of the Looker interface.
2. Select Connections.
3. Click Add Connection. A Configuration Section will open up where you will be required to fill the connection details below. For more details see here.
- Name: Give the connection an Arbitrary name.
- Dialect: Select Snowflake.
- Host: It is of the format <account_name>.snowflakecomputing.com. See here to validate your host value.
- Port: The default is 443.
- Database: Provide the name of the default database that is required for use. Note that this field is case-sensitive.
- Schema: This the default Database Schema that is used in your Snowflake Deployment.
- Authentication: Select Database Account or OAuth:
Use Database Account to specify the Username and Password of the Snowflake user account that will be used to connect to Looker.
Follow the steps below to get credentials to use OAuth for the connection.
To set up an OAuth based connection, you will require a user account with ACCOUNTADMIN permission on Snowflake. Firstly you are required to run the following command in Snowflake, where <looker_hostname> is the hostname of the Looker Instance:
To obtain the OAuth Client ID and Client Secret, you need to run the following command:
Paste in the OAUTH_CLIENT_ID and OAUTH_CLIENT_SECRET values in the Looker OAuth fields.
- Enable PDTs: Use this to enable persistent derived tables (PDTs). See here for more information.
- Temp Database: If PDTs [Persistent Derived Tables] are enabled, this section needs to be set to a Database Schema where the user has full privileges to create, drop, rename, and alter tables.
- (Optional) Max Connections per node: See more about this here.
- Database Time Zone: Default is UTC.
- Query Time Zone: Default is UTC.
- Additional JDBC parameters: Add additional JDBC parameters from the Snowflake JDBC driver.
Add warehouse=<YOUR WAREHOUSE NAME>.
Additionally, by default, Looker will set the following Snowflake parameters on each session:
- TIMESTAMP_TYPE_MAPPING=TIMESTAMP_LTZ
- JDBC_TREAT_DECIMAL_AS_INT=FALSE
- TIMESTAMP_INPUT_FORMAT=AUTO
- AUTOCOMMIT=TRUE
You can override each of these parameters by setting an alternative value in the Additional JDBC parameters field, for example: &AUTOCOMMIT=FALSE
Click on Test to check if the connection is Successful. For troubleshooting, see here.
Click Connect to save these settings.
Now that the connection to Snowflake has been created, you are good to go to explore your Snowflake data in Looker.
Next Steps
Once you've set up and launched this initial integration, the real power lies in its adaptability and extensibility. Here’s a roadmap to help you customize and harness this project tailored to your specific data needs:
Create dbt Sources for Airbyte Data:
Your raw data extracted via Airbyte can be represented as sources in dbt. Start by creating new dbt sources to represent this data, allowing for structured transformations down the line.
Add Your dbt Transformations:
With your dbt sources in place, you can now build upon them. Add your custom SQL transformations in dbt, ensuring that you treat the sources as an upstream dependency. This ensures that your transformations work on the most up-to-date raw data.
Execute the Pipeline in Dagster:
Navigate to the Dagster UI and click on "Materialize all". This triggers the entire pipeline, encompassing the extraction via Airbyte, transformations via dbt, and any other subsequent steps.
Explore in Looker:
You can use the SQL Runner to create queries and Explores, create and share Looks (reports and dashboards), or use LookML to create a data model that Looker will use to query your data. However way you wish to go with your Snowflake data, the choice is yours.
Extend the Project:
The real beauty of this integration is its extensibility. Whether you want to add more data sources, integrate additional tools, or enhance your transformation logic – the floor is yours. With the foundation set, sky's the limit for how you want to extend and refine your data processes.
Getting started is easy
Start breaking your data siloes with Airbyte




